What Parents Can Do When Bullying is Downplayed at School | Psychology Today
Despite the “Bully-Free Zone” posters that line the school cafeteria walls and the Zero-Tolerance policy that was boasted about during last September’s Back-to-School night, your experience is that the school would rather not address the problem at all. The responses you get from your child’s teacher include bland lip service […]
Good advice for this nasty situation — I’m thankfully not facing it myself, but bookmarking just in case…(tags: bullyingkidsschooleducationpsychologychildrenparenting)
Cyclists: Let’s Talk About Shoaling
You’re stopped at a red light with a bunch of folks on bikes, when someone who’s just arrived sails past everyone, right to the head of the class. It’s a lot like seeing somebody in the Whole Foods express lane with too many things. In other words, it’s the kind of behavior that triggers toothy-toddler rages in otherwise emotionally competent adults.
Oh god. This drives me nuts. (via Mark)Commodore 64 Raspberry Pi Case with working power LED
3D-printed retro-pi cases (via Oisin)
(tags: via:oisin3d-printingretropicasesraspberry-pihardwarecute)
↧
Justin Mason: Links for 2017-10-17
↧
Justin Mason: Links for 2017-10-18
The Best Way to Sous Vide Is to Shut Up About It
lol
“1 like = 1 delicious cocktail recipe or booze fact.”
Great cocktail factoid thread from Manhattans Project/Every Cloud’s Felix Cohen
Alarm systems alarmingly insecure. Oh the irony | Pen Test Partners
Some absolutely abysmal security practices used in off-the-shelf self-installed wireless home alarm systems — specifically the Yale HSA6400. Simple replay attacks of the unlock PIN message, for instance
↧
↧
Justin Mason: Links for 2017-10-19
Open-sourcing RacerD: Fast static race detection at scale | Engineering Blog | Facebook Code
At Facebook we have been working on automated reasoning about concurrency in our work with the Infer static analyzer. RacerD, our new open source race detector, searches for data races — unsynchronized memory accesses, where one is a write — in Java programs, and it does this without running the program it is analyzing. RacerD employs symbolic reasoning to cover many paths through an app, quickly.
This sounds extremely interesting…(tags: racerdrace-conditionsdata-racesthread-safetystatic-code-analysiscodingtestingfacebookopen-sourceinfer)
Fascinating stuff — from Felix Cohen’s excellent twitter thread.
Solera is a process for aging liquids such as wine, beer, vinegar, and brandy, by fractional blending in such a way that the finished product is a mixture of ages, with the average age gradually increasing as the process continues over many years. The purpose of this labor-intensive process is the maintenance of a reliable style and quality of the beverage over time. Solera means literally “on the ground” in Spanish, and it refers to the lower level of the set of barrels or other containers used in the process; the liquid (traditionally transferred from barrel to barrel, top to bottom, the oldest mixtures being in the barrel right “on the ground”), although the containers in today’s process are not necessarily stacked physically in the way that this implies, but merely carefully labeled. Products which are often solera aged include Sherry, Madeira, Lillet, Port wine, Marsala, Mavrodafni, Muscat, and Muscadelle wines; Balsamic, Commandaria, some Vins doux naturels, and Sherry vinegars; Brandy de Jerez; beer; rums; and whiskies. Since the origin of this process is undoubtedly out of the Iberian peninsula, most of the traditional terminology was in Spanish, Portuguese, or Catalan.
(tags: wineagingsolerasherrymuscatvinegarbrandybeerrumwhiskeywhiskybrewingspain)
↧
Piergiorgio Lucidi: See you at Open Source Summit Europe

During the next week I'll join the next Open Source Summit Europe in Prague. This year the event will includes different conferences under the same location (Hilton Prague): LinuxCon, ContainerCon, CloudOpen and the new Open Community Conference.
I'm excited to contribute at this event in two different ways on behalf of the Apache Software Foundation:
- As a speaker inside the Open Community Conference
- As a sponsor during MesosCon taking care of the ASF booth duty with Sharan Foga
During my session I'll share the path followed by the Apache ManifoldCF community for achieving the final graduation as a Top Level Project. I'll try to explain what the Apache Way steps are and how we have approached all the challenges during the journey.
The title of the session is The Journey of Apache ManifoldCF: learning from ASF's successes and I'll keep it on Wednesday 25th at 11:15am. If you want to take a look all the schedule please visit the program page.
I would like to thank Apache Community for mentioning me in the article about the Community Development and hope this helps.
Let me know if you come at this event and come to say hello at the booth :)

↧
Stefan Bodewig: XMLUnit.NET 2.5.1 Released
this release fixes a serious bug in the difference engine when documents only differ in namespace prefix.
The full list of changes for XMLUnit.NET:
- elements that only differed in namespace prefix resulted in a false `ELEMENT_TAG_NAME` difference when compared. Issue #22
↧
↧
Justin Mason: Links for 2017-10-20
IBM broke its cloud by letting three domain names expire – The Register
“multiple domain names were mistakenly allowed to expire and were in hold status.”
↧
Bryan Pendleton: Bryan's simple rules for online security
I seem to be posting a lot less frequently recently. I was traveling, work has been crazy busy, you know how it goes. Oh, well.
I was looking at some stuff while I was traveling, and reviewing what I thought, and decided it still holds, so I decided to post it here.
It ain't perfect, but then nothing is, and besides which you get what you paid for, so here are my 100% free of charge simple rules for online security:
- Always do your banking and other important web accesses from your own personal computer, not from public computers like those in hotel business centers, coffee shops, etc.
- Always use Chrome or Firefox to access "important" web sites like the bank, credit cards, Amazon, etc.
- Always use https:// URLs for those web sites
- Always let Windows Update automatically update your computer as it wants to, also always let Chrome and Firefox update themselves when they want to.
- Stick with GMail, it's about as secure as email can get right now. Train yourself to be suspicious of weird mails from unknown senders, or with weird links in them, just in case you get a "phishing" mail that pretends to be from your bank or credit card company, etc.
- If you get a mail from a company you care about (bank, retirement account, credit card, health care company, etc.), instead of clicking on the link in the mail, ALWAYS open up a new browser window and type in the https:// URL of the bank or whatever yourself. It's clicking the link in the email that gets you in trouble.
- At least once a week or so, sign on and look at your credit card charges, your bank account, your retirement account, etc., just to see that everything on there looks as it should be. If not, call your bank and credit card company, dispute the charge, and ask them to send you a new credit card, ATM card, whatever it was.
- Don't accept phone calls from people who aren't in your contacts, or whose call you didn't expect. If you accept a phone call that you think might be legitimate (e.g., from your bank or credit card company), but you need to discuss your account, hang up and call them back, using the main service number from their web site, not the number that called you. Never answer "security questions" over the phone unless you initiated the call yourself. Con artists that call you on the phone can be really persuasive, this is actually the biggest threat nowadays I think.
↧
Bryan Pendleton: Abaddon's Gate: a very short review
Book three of the Expanse series is Abaddon's Gate.
Abaddon's Gate starts out as a continuation of books one and two.
Which is great, and I would have been just fine with that.
But then, about halfway through (page 266, to be exact), Abaddon's Gate takes a sudden and startling 90 degree turn, revealing that much of what you thought you knew from the first two books is completely wrong, and exposing a whole new set of ideas to contemplate.
And so, then, off we go, in a completely new direction!
One of the things I'm really enjoying about the series is the "long now" perspective that it takes. You might think that a couple thousand years of written history is a pretty decent accomplishment for a sentient species, but pah! that's really nothing, in the big picture of things.
If you liked the first two books, you'll enjoy Abaddon's Gate. If you didn't like any of this, well, you probably figured that out about 50 pages into Leviathan Wakes and that's fine, too.
↧
Claus Ibsen: Working with large messages using Apache Camel and ActiveMQ Artemis improved in upcoming Camel 2.21 release
Historically the Apache ActiveMQ message broker was originally created in a time where large messages was measured in MB and not in GB as you may do today.
This is not the case with the next generation broker Apache ActiveMQ Artemis (or just Artemis) which has much better support for large messages.
So its about time that the Camel team finally had some time to work on this to ensure Camel work well with Artemis and large messages. This work was committed this weekend and we provided an example to demonstrate this.
The example runs Camel with the following two small routes:
![]()
The first route just route files to a queue on the message broker named data. The 2nd route does the opposite, routes from the data queue to file.This is not the case with the next generation broker Apache ActiveMQ Artemis (or just Artemis) which has much better support for large messages.
So its about time that the Camel team finally had some time to work on this to ensure Camel work well with Artemis and large messages. This work was committed this weekend and we provided an example to demonstrate this.
The example runs Camel with the following two small routes:

Pay attention to the 2nd route as it has turned on Camel's stream caching. This ensures that Camel will deal with large streaming payloads in a manner where Camel can automatic spool big streams to temporary disk space to avoid taking up memory. The stream caching in Apache Camel is fully configurable and you can setup thresholds that are based on payload size, memory left in the JVM etc to trigger when to spool to disk. However the default settings are often sufficient.
Camel then uses the JMS component to integrate with the ActiveMQ Artemis broker which you setup as follows:

This is all standard configuration (you should consider setting up a connection pool as well).
The example requires to run a ActiveMQ Artemis message broker separately in a JVM, and then start the Camel JVM with a lower memory setting such as 128mb or 256mb etc which can be done via Maven:
export MAVEN_OPTS="-Xmx256m"
And then you run Camel via Maven
mvn camel:run
When the application runs, you can then copy big files to the target/inbox directory, which should then stream these big messages to the Artemis broker, and then back again to Camel which will then save this to the target/outbox directory.
For example I tired this by copying a 1.6gb docker VM file, and Camel will log the following:
INFO Sending file disk.vmdk to Artemis
INFO Finish sending file to Artemis
INFO Received data from Artemis
INFO Finish saving data from Artemis as file
And we can see the file is saved again, and its also the correct size of 1.6gb
$ ls -lh target/outbox/
total 3417600
-rw-r--r-- 1 davsclaus staff 1.6G Oct 22 14:39 disk.vmdk
I attached jconsole to the running Camel JVM and monitored the memory usage which is shown in the graph:

The graph shows that the heap memory peaked at around 130mb and that after GC its back down to around 50mb. The JVM is configured with a max of 256mb.
You can find detailed step by step instructions with the example how exactly to run the example, so you can try for yourself. The example is part of the upcoming Apache Camel 2.21 release, where the camel-jms component has been improved for supporting javax.jms.StreamMessage types and has special optimisation for ActiveMQ Artemis as demonstrated by this example.
PS: The example could be written in numerous ways, but instead of creating yet another Spring Boot based example we chose to just use plain XML. In the end Camel does not care, you can implement and use Camel anyhow you like.
↧
↧
Phil Steitz: Selling the truth
This month's Significance magazine includes a jarring article about fake news. As one would expect in Significance, there is interesting empirical data in the article. What I found most interesting was the following quote attributed to Dorothy Byrne, a British broadcast journalism leader:
The lesson learned here is that in debunking fake news, "factual outrage" is not enough - we need to focus on selling the truth as the more emotionally satisfying position. As the Significance article points out, people are drawn to simple explanations and beliefs that fit with what they want to be true. So to repair the damage of fake news, we have to not just show people that their beliefs are inconsistent with reality - we need to provide them with another, emotionally acceptable reality that is closer to the truth.
"You can't just feed people a load of facts...we are social animals, we relate to other people, so we have to always have a mixture of telling people's human stories while at the same time giving context to those stories and giving the real facts."Just presenting and objectively supporting debunking factual evidence is not sufficient. We need to acknowledge that just as emotional triggers are key to spreading fake news, so they need to be considered in repairing the damage. I saw a great example of that in yesterday's Wall Street Journal. An article, titled "Video Contradicts Kelly's Criticism of Congresswoman," sets out to debunk the fake news story promulgated by the Trump administration claiming that Florida Rep. Frederica Wilson had touted her personal efforts in getting funding for an FBI building in her district while not acknowledging the slain FBI agents for whom the building was named. The Journal article could have stopped at the factual assertions that she had not been elected when the funding was approved and that a video of the speech she gave includes her acknowledging the agents. But it goes on to provide emotive context, describing the Congresswoman's lifelong focus on issues affecting low-income families and her personal connection with Army Sgt. La David Johnson, the Green Beret whose passing ultimately led to her confrontation with the Trump administration. The details on how she had known Sgt. Johnson's family for generations and that he himself had participated in a mentoring program that she founded provided context for the facts. The emotive picture painted by the original fake news claim and the administration's name-calling "all hat, no cattle" was replaced with the image of a caring human being. In that light, it's easier to believe the truth - that Rep. Wilson was gracious and respectful of the fallen agents and their families just as she was of Sgt. Johnson and his family.
The lesson learned here is that in debunking fake news, "factual outrage" is not enough - we need to focus on selling the truth as the more emotionally satisfying position. As the Significance article points out, people are drawn to simple explanations and beliefs that fit with what they want to be true. So to repair the damage of fake news, we have to not just show people that their beliefs are inconsistent with reality - we need to provide them with another, emotionally acceptable reality that is closer to the truth.
↧
Shawn McKinney: Why I love LDAPCon
This post is loosely based on a lightning talk last week in Brussels. We had a few minutes to fill and I felt compelled to spill my guts, despite having nothing prepared.
For those that have never heard about LDAPCon, it’s a biennial event, first held in ’07, with rotating venues, always in interesting places. The talks are a 50/50 split between technology providers and usages.
You can check out this year’s talks, along with sides — here.
It’s not a ‘big’ conference — attendance hovers between 70 and 80. It doesn’t last very long — about two days. There’s very little glitz or glory. You won’t find the big vendors with their entourages of executives and marketing reps, wearing fancy suits, sporting fast talk and empty promises. Nor are there giveaways, flashy parties or big name entertainers. For the most part the media and analysts ignore it; participants don’t get much exposure to the outside world. Everyone just sits in a single, large conference room for the duration and listens to every talk (gasp).
So what is it about this modest little gathering that I love so much?
Not my first rodeo. The end of my career is much closer than its beginning, and I’ve been to dozens of conferences over the decades. Large, small and everything in between. For example, I’ve attended JavaOne twelve times and been to half a dozen IBM mega conferences.
Let’s start with relevance. Contrary to what you may think LDAP is not going away. It’s not sexy or exciting. Depending on your role in technology you may not even have heard of it (although I can guarantee that your information is housed within its walls). But it’s useful. If you’re interested in security you better understand LDAP. If you choose not to use it you better have good reasons. Ignore at your peril.
I’ve been working with LDAP technology (as a user) for almost twenty years. When I first started, back in the late ’90’s there was a fair amount of hype behind it. Over the years that hype has faded of course. As it faded, I found myself alone in the tech centers. In other words, I was the only one who understood how it worked, and why it was needed. As the years passed, I found my knowledge growing stale. Without others to bounce ideas off of there’s little chance for learning. You might say I was thirsting for knowledge.
My first LDAPCon was back in ’11 in Heidelberg. It was as if I had found an oasis after stumbling about in the desert alone for years. It was like AH at last others who understand and from whom I can learn.
Many conferences are rather impersonal. This is understandable of course, because the communities aren’t well established or are so large that it would be impossible to know everyone, or even a significant minority.
The leaders of these large technology communities are more like rock stars than ordinary people. Often (not always) with oversized egos fed by the adoration of their ‘fans’. This is great if you are seeking an autograph or inspiration, but not so much if you’re wanting help or validation of ideas.
Not the case at LDAPCon. You’ll still find the leaders and architects, but not the egos. Rather, they understand the importance of helping others find their way and encourage interaction and collaboration.
Sprinkle in with these leaders earnest newcomers. Much like when I arrived in Heidelberg the pattern repeats. These newcomers bring energy and passion that fuels the ecosystem and helps to stave off obsolescence. There is a continuous stream of ideas coming in ensuring the products and protocols remain relevant.
The newcomers are welcomed with open arms and not ignored or marginalized. This creates a warm atmosphere of collaboration. New ideas are cherished and not shunned. Newcomers are elevated and not marginalized.
Not a marketing conference. You won’t find booths (like at a carnival) where passersby are cajoled and enticed by shiny lights and glitzy demos. Where on the last day they warily pack up their rides and go to the next stop on the circuit.
Not a competitive atmosphere, rather collaborative. Here is where server vendors like Forgerock, Redhat, Microsoft, Symas, and others meet to work together on common goals, improving conditions for the community. They don’t all show up to every one, but are certainly welcome when they do.
Here, on the last day, there is some sadness. We go and have some beer together, share war stories (one last time) and make plans for the future.
The next LDAPCon will probably again be held in Europe. Perhaps Berlin or Brno.
I can hardly wait.



↧
Isabel Drost: Open Source Summit Prague 2017 - part 1
Open Source Summit, formerly known as LinuxCon, this year took place in Prague.
Drawing some 2000 attendees to the lovely Czech city, the conference focussed on
all things Linux kernel, containers, community and governance.
The first day started with three crowded keynotes: First one by Neha Narkhede on
The third keynote of the morning was given by Jono Bacon on what it takes to incentivise communities - be it open source communities, volunteer run organisations or corporations. According to his perspective there are four major factors that drive human actions:
When it comes to the process of incentivising people Jono proposed a three step model: From hook to reason to reward.
Hook here means a trigger. What triggers the incentivising process? You can look at how people participate - number of pull requests, amount of documentation contributed, time spent giving talks at conferences. Those are all action based triggers. What's often more valuable is to look out for validation based triggers: Pull requests submitted, reviewed and merged. He showed an example of a public hacker leaderboard that had their evaluation system published. While that's lovely in terms of transparency IMHO it has two drawbacks: It makes it much easier to evaluate known wanted contributions than what people might not have thought about being a valuable contribution when setting up the leadership board. With that it also heavily influences which contribtions will come in and might invite a "hack the leadership board" kind of behaviour.
When thinking about reason there are two types of incentives: The reason could be invisible up-front, Jono called this submarine rewards. Without clear prior warning people get their reward for something that was wanted. The reason could be stated up front: "If you do that, then you'll get reward x". Which type to choose heavily depends on your organisation, the individual giving out the reward as well as the individual receiving the reward. The deciding factor often is to be found in which is more likely authentic to your organisation.
In terms of reward itself: There are extrinsic motivators - swag like stickers, t-shirts, give-aways. Those tend to be expensive, in particular if shipping them is needed. Something that in professional open source projects is often overlooked are intrinsic rewards: A Thank You goes a long way. So does a blog post. Or some social media mention. Invitations help. So do referrals to ones own network. Direct lines to key people help. Testimonials help.
Overall measurement is key. So is concentrating on focusing on incentivising shared value.
In his talk, Matthias Kirschner gave an overview of Limux - the Linux rolled out for the Munich administration project. How it started, what went wrong during evaluation, which way political forces were drawing.
What I found very interesting about the talk were the questions that Matthias raised at the very end:
As a lesson from these events, the FSFE launched an initiative to drive developing code funded by public money under free licenses.
Coming from a virtual machine based world where apps are tied to virtual machines who themselves are tied to physical machines, what projects like Apache Mesos try to do is to abstract that exact machine mapping away. Is a first result from this decision, how to communicate between micro services becomes a lot less obvious. This is where service discovery enters the stage.
When running in a microservice environment one goal when assigning tasks to services is to avoid unhealthy targets. In terms of resource utilization instead of overprovisioning the goal is to use just the right amount of your resources in order to avoid wasting money on idle resources. Individual service overload is to be avoided.
Looking at an example of three physical hosts running three services in a redundant matter, how can assigning tasks to these instances be achieved?
In both solutions you will also still have logic e.g. for de-registrating services. You will have to make sure to register your service only once is successfully booted up.
Enter the Service Mesh architecture, e.g. based on Linker.d, or Envoy. The idea here is to have what Tomek called a sidecar added to each service that talks to the service mesh controller to take care of service discovery, health checking, routing, load balancing, authn/z, metrics and tracing. The service mesh controller will hold information on which services are available, available load balancing algorithms and heuristics, repeating, timeouts and circuit breaking, as well as deployments. As a result the service itself no longer has to take care of load balancing, ciruict breaking, repeating policies, or even tracing.
After that high level overview of where microservice orchestration can take you, I took a break, following a good friend to the Introduction to SoC+FPGA talk. It's great to see Linux support for these systems - even if not quite as stable as would be an ideal world case.
The topic is interesting for a number of reasons: As early as back in 2008 MIT developed something called Ksplice which uses jumps patched into functions for call redirection. The project was aquired by Oracle - and discontinued.
In 2014 SuSE came up with something called kGraft for Linux live patching based on immediate patching but lazy migration. At the same time RedHat developed kpatch based on an activeness check.
In the case of kGraft the goal was to be able to apply limited scope fixes to the Linux kernel (e.g. for security, stability or corruption fixes), require only minimal changes to the source code, have no runtime cost impact, no interruption to applications while patching, and allow for full review of patch source code.
The way it is implemented is fairly obvious - in hindsight: It's based on re-useing the ftrace framework. kGraft uses the tracer for inception but then asks ftrace to return back to a different address, namely the start of the patched function. So far the feature is available for x86 only.
Now while patching a single function is easy, making changes that affect multiple funtions get trickier. This means a need for lazy migration that ensures function type safety based on a consistency model. In kGraft this is based on a per-thread flag that marks all tasks in the beginning and makes waiting for them to be migrated possible.
From 2014 onwards it took a year to get the ideas merged into mainline. What is available there is a mixture of both kGraft and kpatch.
What are the limitations of the merged approach? There is no way right now to deal with data structure changes, in particular when thinking about spinlocks and mutexes. Consistency reasoning right now is done manually. Architectures other than X86 are still an open issue. Documentation and better testing are open tasks.
Keynotes
Apache Kafka and the Rise of the Streaming Platform. Second one by Reuben Paul (11 years old) on how hacking today really is just childs play: The hack itself might seem like toying around (getting into the protocol of children's toys in order to make them do things without using the app that was intended to control them). Taken into the bigger context of a world that is getting more and more interconnected - starting with regular laptops, over mobile devices to cars and little sensors running your home the lack of thought that goes into security when building systems today is both startling and worrying at the same time.The third keynote of the morning was given by Jono Bacon on what it takes to incentivise communities - be it open source communities, volunteer run organisations or corporations. According to his perspective there are four major factors that drive human actions:
- People thrive for acceptance. This can be exploited when building communities: Acceptance is often displayed by some form of status. People are more likely to do what makes them proceed in their career, gain the next level in a leadership board, gain some form of real or artificial title.
- Humans are a reciprocal species. Ever heart of the phrase "a favour given - a favour taken"? People who once received a favour from you are more likely to help in the long run.
- People form habits through repetition - but it takes time to get into a habit: You need to make sure people repeat the behaviour you want them to show for at least two months until it becomes a habit that they themselves continue to drive without your help. If you are trying to roll out peer review based, pull request based working as a new model - it will take roughly two months for people to adapt this as a habit.
- Humans have a fairly good bullshit radar. Try to remain authentic, instead of automated thank yous, extend authentic (I would add qualified) thank you messages.
When it comes to the process of incentivising people Jono proposed a three step model: From hook to reason to reward.
Hook here means a trigger. What triggers the incentivising process? You can look at how people participate - number of pull requests, amount of documentation contributed, time spent giving talks at conferences. Those are all action based triggers. What's often more valuable is to look out for validation based triggers: Pull requests submitted, reviewed and merged. He showed an example of a public hacker leaderboard that had their evaluation system published. While that's lovely in terms of transparency IMHO it has two drawbacks: It makes it much easier to evaluate known wanted contributions than what people might not have thought about being a valuable contribution when setting up the leadership board. With that it also heavily influences which contribtions will come in and might invite a "hack the leadership board" kind of behaviour.
When thinking about reason there are two types of incentives: The reason could be invisible up-front, Jono called this submarine rewards. Without clear prior warning people get their reward for something that was wanted. The reason could be stated up front: "If you do that, then you'll get reward x". Which type to choose heavily depends on your organisation, the individual giving out the reward as well as the individual receiving the reward. The deciding factor often is to be found in which is more likely authentic to your organisation.
In terms of reward itself: There are extrinsic motivators - swag like stickers, t-shirts, give-aways. Those tend to be expensive, in particular if shipping them is needed. Something that in professional open source projects is often overlooked are intrinsic rewards: A Thank You goes a long way. So does a blog post. Or some social media mention. Invitations help. So do referrals to ones own network. Direct lines to key people help. Testimonials help.
Overall measurement is key. So is concentrating on focusing on incentivising shared value.
Limux - the loss of a lighthouse
In his talk, Matthias Kirschner gave an overview of Limux - the Linux rolled out for the Munich administration project. How it started, what went wrong during evaluation, which way political forces were drawing.
What I found very interesting about the talk were the questions that Matthias raised at the very end:
- Do we suck at desktop? Are there too many depending apps?
- Did we focus too much on the cost aspect?
- Is the community supportive enough to people trying to monetise open source?
- Do we harm migrations by volunteering - as in single people supporting a project without a budget, burning out in the process instead of setting up sustainable projects with a real budget? Instead of teaching the pros and cons of going for free software so people are in a good position to argue for a sustainable project budget?
- Within administrations: Did we focus too much on the operating system instead of freeing the apps people are using on a day to day basis?
- Did we focus too much on one star project instead of collecting and publicising many different free software based approaches?
As a lesson from these events, the FSFE launched an initiative to drive developing code funded by public money under free licenses.
Dude, Where's My Microservice
In his talk Dude, Where's My Microservice? - Tomasz Janiszewski from Allegro gave an introduction to what projects like Marathon on Apache Mesos, Docker Swarm, Kubernetes or Nomad can do for your Microservices architecture. While the examples given in the talk refer to specific technologies, they are intented to be general purpose.Coming from a virtual machine based world where apps are tied to virtual machines who themselves are tied to physical machines, what projects like Apache Mesos try to do is to abstract that exact machine mapping away. Is a first result from this decision, how to communicate between micro services becomes a lot less obvious. This is where service discovery enters the stage.
When running in a microservice environment one goal when assigning tasks to services is to avoid unhealthy targets. In terms of resource utilization instead of overprovisioning the goal is to use just the right amount of your resources in order to avoid wasting money on idle resources. Individual service overload is to be avoided.
Looking at an example of three physical hosts running three services in a redundant matter, how can assigning tasks to these instances be achieved?
- One very simple solution is to go for a proxy based architecture. There will be a single point of change, there aren't any in-app dependencies to make this model work. You can implement fine-grained load balancing in your proxy. However this comes at the cost of having a single point of failure, one additional hop in the middle, and usually requires using a common protocol that the proxy understands.
- Another approach would be to go for a DNS based architecture: Have one registry that holds information on where services are located, but talking to these happens directly instead of through a proxy. The advantages here: No additional hop once the name is resolved, no single point of failure - services can work with stale data, it's protocol independent. However it does come with in-app dependencies. Load balancing has to happen local to the app. You will want to cache name resolution results, but every cache needs some cache invalidation strategy.
In both solutions you will also still have logic e.g. for de-registrating services. You will have to make sure to register your service only once is successfully booted up.
Enter the Service Mesh architecture, e.g. based on Linker.d, or Envoy. The idea here is to have what Tomek called a sidecar added to each service that talks to the service mesh controller to take care of service discovery, health checking, routing, load balancing, authn/z, metrics and tracing. The service mesh controller will hold information on which services are available, available load balancing algorithms and heuristics, repeating, timeouts and circuit breaking, as well as deployments. As a result the service itself no longer has to take care of load balancing, ciruict breaking, repeating policies, or even tracing.
After that high level overview of where microservice orchestration can take you, I took a break, following a good friend to the Introduction to SoC+FPGA talk. It's great to see Linux support for these systems - even if not quite as stable as would be an ideal world case.
Trolling != Enforcement
The afternoon for me started with a very valuable talk by Shane Coughlan on how Trolling doesn't equal enforcement. This talk was related to what was published on LWN earlier this year. Shane started off by explaining some of the history of open source licensing, from times when it was unclear if documents like the GPL would hold in front of courts, how projects like gplviolations.org proofed that indeed those are valid legal contracts that can be enforced in court. What he made clear was that those licenses are the basis for equal collaboration: They are a common set of rules that parties not knowing each other agree to adhere to. As a result following the rules set forth in those licenses does create trust in the wider community and thus leads to more collaboration overall. On the flipside breaking the rules does erode this very trust. It leads to less trust in those companies breaking the rules. It also leads to less trust in open source if projects don't follow the rules as expected. However when it comes to copyright enforcement, the case of Patrick McHardy does imply the question if all copyright enforcement is good for the wider community. In order to understand that question we need to look at the method that Patrick McHardy employs: He will get in touch with companies for seemingly minor copyright infringements, ask for a cease and desist to be signed and get a small sum of money out of his target. In a second step the process above repeats, except the sum extracted increases. Unfortunately with this approach what was shown is that there is a viable business model that hasn't been tapped into yet. So while the activities by Patrick McHardy probably aren't so bad in and off itself, they do set a precedent that others might follow causing way more harm. Clearly there is no easy way out. Suggestions include establishing common norms for enforcement, ensuring that hostile actors are clearly unwelcome. For companies steps that can be taken include understanding the basics of legal requirements, understanding community norms, and having processes and tooling to address both. As one step there is a project called Open Chain publishing material on the topic of open source copyright, compliance and compliance self certification.Kernel live patching
Following Tomas Tomecek's talk on how to get from Dockerfiles to Ansible Containers I went to a talk that was given by Miroslav Benes from SuSE on Linux kernel live patching.The topic is interesting for a number of reasons: As early as back in 2008 MIT developed something called Ksplice which uses jumps patched into functions for call redirection. The project was aquired by Oracle - and discontinued.
In 2014 SuSE came up with something called kGraft for Linux live patching based on immediate patching but lazy migration. At the same time RedHat developed kpatch based on an activeness check.
In the case of kGraft the goal was to be able to apply limited scope fixes to the Linux kernel (e.g. for security, stability or corruption fixes), require only minimal changes to the source code, have no runtime cost impact, no interruption to applications while patching, and allow for full review of patch source code.
The way it is implemented is fairly obvious - in hindsight: It's based on re-useing the ftrace framework. kGraft uses the tracer for inception but then asks ftrace to return back to a different address, namely the start of the patched function. So far the feature is available for x86 only.
Now while patching a single function is easy, making changes that affect multiple funtions get trickier. This means a need for lazy migration that ensures function type safety based on a consistency model. In kGraft this is based on a per-thread flag that marks all tasks in the beginning and makes waiting for them to be migrated possible.
From 2014 onwards it took a year to get the ideas merged into mainline. What is available there is a mixture of both kGraft and kpatch.
What are the limitations of the merged approach? There is no way right now to deal with data structure changes, in particular when thinking about spinlocks and mutexes. Consistency reasoning right now is done manually. Architectures other than X86 are still an open issue. Documentation and better testing are open tasks.
↧
Steve Loughran: ROCA breaks my commit process
Since January I've been signing my git commits to the main Hadoop branches; along with Akira, Aaron and Allen we've been leading the way in trying to be more rigorous about authenticating our artifacts, in that gradual (and clearly futile) process to have some form of defensible INFOSEC policy on the development laptop (and ignoring homebrew, maven, sbt artifact installation,...).
For extra rigorousness, I've been using a Yubikey 4 for the signing: I don't have the secret key on my laptop *at all*, just the revocation secrets. To sign work, I use "git commit -S", the first commit of the day asks me to press the button and enter a PIN, from then on all I have to do to sign a commit is just press the button on the dongle plugged into a USB port on the monitor. Simple, seamless signing.
![Yubikey rollout]()
Until Monday October 16, 2017.
There was some news in the morning about a WPA2 vulnerability. I looked at the summary and opted not to worry; the patch status of consumer electronics on the WLAN is more significant a risk than the WiFI password. No problem there, more a moral "never trust a network". As for a hinted at RSA vulnerability, it was going to inevitably be of two forms "utter disaster there's no point worrying about" or "hypothetical and irrelevant to most of us." Which is where I wasn't quite right.
Later on in the afternoon, glancing at fb on the phone and what I should I see but a message from facebook.
![Your OpenPGP public key is weak. Please revoke it and generate a replacement]()
"Your OpenPGP public key is weak. Please revoke it and generate a replacement"
That's not the usual FB message. I go over to a laptop, log in to facebook and look at my settings: yes, I've pasted the public key in there. Not because I want encrypted comms with FB, but so that people can see if they really want to; part of my "publish the key broadly" program, as I've been trying to cross-sign/cross-trust other ASF committers' keys.
Then over to twitter and computing news sites and yes, there is a bug in a GPG keygen library used in SoC parts, from Estonian ID cards to Yubikeys like mine. And as a result, it is possible for someone to take my public key and generate the private one. While the vulnerability is public, the exact algorithm to regenerate the private key isn't so I have a bit of time left to kill my key. Which I do, and place an order for a replacement key (which has arrived)
And here's the problem. Git treats the revocation of a key as a sign that every single signature most now be untrusted.
Before, a one commit-per-line log of branch-2 --show-signature
![git log --1show-signatures branch-2]()
After
![git log1 --show-signature after revocation picked up]()
You see the difference? All my commits are now considered suspect. Anyone doing a log --show-signature will now actually get more warnings about the commits I signed than all those commits by other people which are not signed at all. Even worse, if someone were to ever try to do a full validation of the commit path at any time in the future is now going to see this. For the entire history of the git repo, those commits of mine are going to show up untrusted.
Given the way that git overreacts to key revocation, I didn't do this right.
What I should have done is simpler: force-expired the key by changing its expiry date the current date/time and pushing up the updated public key to the servers. As people update their keytabs from the servers, they'll see that the key isn't valid for signing new data, but that all commits issued by the user are marked as valid-at-the-time-but-with-an-expired-key. Key revocation would be reserved for the real emergency, "someone has my key and is actively using it".
I now have a new key, and will be rolling it out, This time I'm thinking ofr rolling my signing key every year, so that if I ever do have to revoke a key, it's only the last year's worth of commits which will be invalidated.
For extra rigorousness, I've been using a Yubikey 4 for the signing: I don't have the secret key on my laptop *at all*, just the revocation secrets. To sign work, I use "git commit -S", the first commit of the day asks me to press the button and enter a PIN, from then on all I have to do to sign a commit is just press the button on the dongle plugged into a USB port on the monitor. Simple, seamless signing.

Until Monday October 16, 2017.
There was some news in the morning about a WPA2 vulnerability. I looked at the summary and opted not to worry; the patch status of consumer electronics on the WLAN is more significant a risk than the WiFI password. No problem there, more a moral "never trust a network". As for a hinted at RSA vulnerability, it was going to inevitably be of two forms "utter disaster there's no point worrying about" or "hypothetical and irrelevant to most of us." Which is where I wasn't quite right.
Later on in the afternoon, glancing at fb on the phone and what I should I see but a message from facebook.

"Your OpenPGP public key is weak. Please revoke it and generate a replacement"
That's not the usual FB message. I go over to a laptop, log in to facebook and look at my settings: yes, I've pasted the public key in there. Not because I want encrypted comms with FB, but so that people can see if they really want to; part of my "publish the key broadly" program, as I've been trying to cross-sign/cross-trust other ASF committers' keys.
Then over to twitter and computing news sites and yes, there is a bug in a GPG keygen library used in SoC parts, from Estonian ID cards to Yubikeys like mine. And as a result, it is possible for someone to take my public key and generate the private one. While the vulnerability is public, the exact algorithm to regenerate the private key isn't so I have a bit of time left to kill my key. Which I do, and place an order for a replacement key (which has arrived)
And here's the problem. Git treats the revocation of a key as a sign that every single signature most now be untrusted.
Before, a one commit-per-line log of branch-2 --show-signature
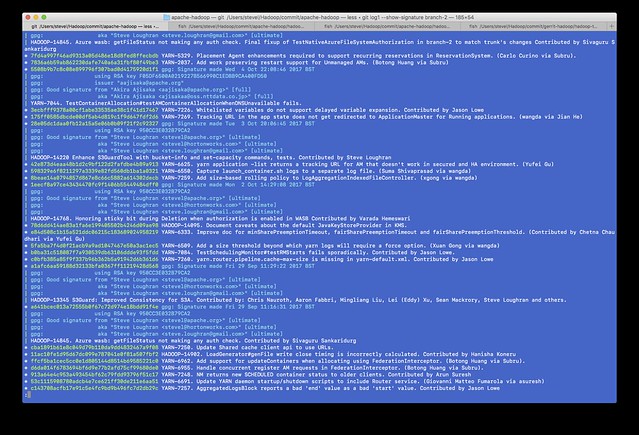
After
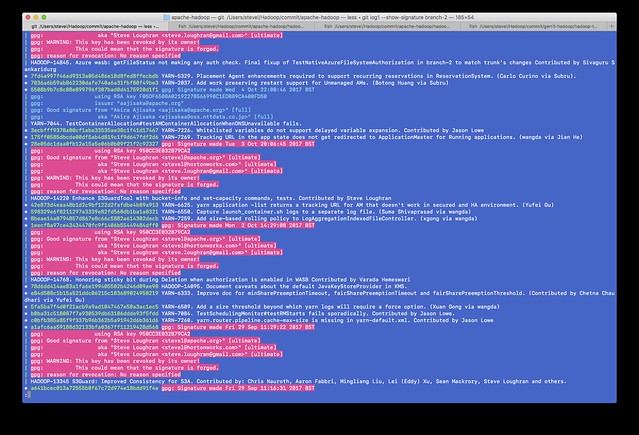
You see the difference? All my commits are now considered suspect. Anyone doing a log --show-signature will now actually get more warnings about the commits I signed than all those commits by other people which are not signed at all. Even worse, if someone were to ever try to do a full validation of the commit path at any time in the future is now going to see this. For the entire history of the git repo, those commits of mine are going to show up untrusted.
Given the way that git overreacts to key revocation, I didn't do this right.
What I should have done is simpler: force-expired the key by changing its expiry date the current date/time and pushing up the updated public key to the servers. As people update their keytabs from the servers, they'll see that the key isn't valid for signing new data, but that all commits issued by the user are marked as valid-at-the-time-but-with-an-expired-key. Key revocation would be reserved for the real emergency, "someone has my key and is actively using it".
I now have a new key, and will be rolling it out, This time I'm thinking ofr rolling my signing key every year, so that if I ever do have to revoke a key, it's only the last year's worth of commits which will be invalidated.
↧
↧
Justin Mason: Links for 2017-10-23
↧
Justin Mason: Links for 2017-10-24
What To Do When Your Daughter Is the Mean Girl | Psychology Today
Bookmarking — just in case. hopefully it won’t be necessary… good site for parenting advice along these lines.
I knew this day would come. I was, of course, hoping it never would-hoping that my daughter would never be mean to someone else’s daughter-but as they say, I wrote the book on girl bullying in elementary school, so I knew that there was a pretty good chance that despite all of my best efforts, one of these days, my girl was gonna act like the mean one. This morning, she told me about it.
MaxMind DB File Format Specification
An interesting data structure format — ‘the MaxMind DB file format is a database format that maps IPv4 and IPv6 addresses to data records using an efficient binary search tree.’
(tags: maxminddatabasesstorageipv4ipv6addressesbstbinary-search-treestreesdata-structures)
↧
Isabel Drost: Open source summit - Day 2
Day two of Open Source summit for me started a bit slow for lack of sleep. The
first talk I went to was on "Developer tools for Kubernetes" by Michelle Noorali
and Matt Butcher. Essentially the two of them showed two projects (Draft and Brigade to help ease development
apps for Kubernetes clusters. Draft here is the tool to use for developing long
running, daemon like apps. Brigade has the goal of making event driven app
development easier - almost like providing shell script like composability to
Kubernetes deployed pipelines.
So what are some of the use cases that Ian saw talking to customers:
Marta went on detailing eight use cases:
The first question revolved around how people had gotten started with open source and kernel development and what advise they would have for newbies. The one advise shared by everyone other than scratch your own itch and find something that interests you: Be persistant. Don't give up.
Talking about release cycles and moving too fast or too slow there was a comment on best practice to get patches into the kernel that I found very valuable: Don't get started coding right away. A lot of waste could have been prevented if people just shared their needs early on and asked questions instead of diving right into coding.
There was discussion on the meaning of long time stability. General consensus seemed to be that long term support really only includes security and stability fixes. No new features. Imaging adding current devices to a 20 year old kernel that doesn't even support USB yet.
There was a lovely quote by Narcisa on the dangers and advantages of using C as a primary coding language: With great power come great bugs.
There was discussion on using "new-fangled" tools like github instead of plain e-mail. Sure e-mail is harder to get into as a new contributor. However current maintainer processes heavily rely on that as a tool for communication. There was a joke about implementing their own tool for that just like was done with git. One argument for using something less flexible that I found interesting: Aparently it's hard to switch between subsystems just because workflows differ so much, so agreeing on a common workflow would make that easier.Asked for what would happen if Linus was eaten by a shark when scuba diving
the answer was interesting: Likely at first there would be a hiding game because
nobody would want to take up his work load. Next there would likely develop a
team of maintainers collaborating in a consensus based model to keep up with
things.
In terms of testing - that depend heavily on hardware being available to
test on. Think like the kernel CI community help a lot with that.
I closed the day going to Zaheda Bhorat's talk on "Love would you do - everyday" on her journey in the open source world. It's a great motiviation for people to start contributing to the open source community and become part of it - often for life changing what you do in ways you would never have imagined before. Lots of love for The Apache Software Foundation in it.
Kubernetes in real life
In his talk on K8s in real life Ian Crosby went over five customer cases. He started out by highlighting the promise of magic from K8s: Jobs should automatically be re-scheduled to healthy nodes, traffic re-routed once a machine goes down. As a project it came out of Google as a re-implementation of their internal, 15 years old system called Borg. Currently the governance of K8s lies with the Cloud Native Foundation, part of the Linux Foundation.So what are some of the use cases that Ian saw talking to customers:
- "Can you help us setup a K8s cluster?" - asked by a customer with one monolithic application deployed twice a year. Clearly that is not a good fit for K8s. You will need a certain level of automation, continuous integration and continuous delivery for K8s to make any sense at all.
- There were customers trying to get into K8s in order to be able to hire talent interested in that technology. That pretty much gets the problem the wrong way around. K8s also won't help with organisational problems where dev and ops teams aren't talking with each other.
- The first question to ask when deploying K8s is whether to go for on-prem, hosted externally or a mix of both. One factor pulling heavily towards hosted solution is the level of time and training investment people are willing to make with K8s. Ian told the audience that he was able to migrate a complete startup to K8s within a short period of time by relying on a hosted solution resulting in a setup that requires just one ops person to maintain. In that particular instance the tech that remained on-prem were Elasticsearch and Kafka as services.
- Another client (government related, huge security requirements) decided to go for on-prem. They had strict requirements to not connect their internal network to the public internet resulting in people carrying downloaded software on USB sticks from one machine to the other. The obvious recommendation to ease things at least a little bit is to relax security requirements at least a little bit here.
- In a third use case the customer tried to establish a prod cluster, staging cluster, test cluster, one dev cluster per developer - pretty much turning into a maintainance nightmare. The solution was to go for a one cluster architecture, using shared resources, but namespaces to create virtual clusters, role based access control for security, network policies to restrict which services can talk to each other, service level TLS to get communications secure. Looking at CI this can be taken one level furter even - spinning up clusters on the fly when they are needed for testing.
- In another customer case Java apps were dying randomly - apparently because what was deployed was using the default settings. Lesson learnt: Learn how it works first, go to production after that.
Rebuilding trust through blockchains and open source
Having pretty much no background in blockchains - other than knowing that a thing like bitcoin exists - I decided to go to the introductory "Rebuilding trust through blockchains and open source" talk next. Marta started of by explaining how societies are built on top of trust. However today (potentially accelerated through tech) this trust in NGOs, governments and institutions is being eroded. Her solution to the problem is called Hyperledger, a trust protocol to build an enterprise grade distributed database based on a permissioned block chain with trust built-in.Marta went on detailing eight use cases:
- Cross border payments: Currently, using SWIFT, these take days to complete, cost a lot of money, are complicated to do. The goal with rolling out block chains for this would be to make reconcillation real-time. Put information on a shared ledger to make it audible as well. At the moment ANZ, WellsFargo, BNP Paribas and BNY Mellon are participating in this POC.
- Healthcare records: The goal is to put pointers to medical data on a shared ledger so that procedures like blood testing are being done just once and can be trusted across institutions.
- Interstate medical licensing: Here the goal is to make treatment re-imbursment easier, probably even allowing for handing out fixed-purpose budgets.
- Ethical seafood movement: Here the goal is to put information on supply chains for seafood on a shared ledger to make tracking easier, audible and cheaper. The same applies for other supply chains, think diamonds, coffee etc.
- Real estate transactions: The goal is to keep track of land title records on a shared ledger for easier tracking, auditing and access. Same could be done for certifications (e.g. of academic titles etc.)
- Last but not least there is a POC to how how to use shared ledgers to track ownership of creative works in a distributed way and take the middleman distributing money to artists out of the loop.
Kernel developers panel discussion
For the panel discussion Jonathan Corbet invited five different Linux kernel hackers in different stages of their career, with different backgrounds to answer audience questions. The panel featured Vlastimil Babka, Arnd Bergmann, Thomas Gleixner, Narcisa Vasile, Laura Abbott.The first question revolved around how people had gotten started with open source and kernel development and what advise they would have for newbies. The one advise shared by everyone other than scratch your own itch and find something that interests you: Be persistant. Don't give up.
Talking about release cycles and moving too fast or too slow there was a comment on best practice to get patches into the kernel that I found very valuable: Don't get started coding right away. A lot of waste could have been prevented if people just shared their needs early on and asked questions instead of diving right into coding.
There was discussion on the meaning of long time stability. General consensus seemed to be that long term support really only includes security and stability fixes. No new features. Imaging adding current devices to a 20 year old kernel that doesn't even support USB yet.
There was a lovely quote by Narcisa on the dangers and advantages of using C as a primary coding language: With great power come great bugs.
There was discussion on using "new-fangled" tools like github instead of plain e-mail. Sure e-mail is harder to get into as a new contributor. However current maintainer processes heavily rely on that as a tool for communication. There was a joke about implementing their own tool for that just like was done with git. One argument for using something less flexible that I found interesting: Aparently it's hard to switch between subsystems just because workflows differ so much, so agreeing on a common workflow would make that easier.
I closed the day going to Zaheda Bhorat's talk on "Love would you do - everyday" on her journey in the open source world. It's a great motiviation for people to start contributing to the open source community and become part of it - often for life changing what you do in ways you would never have imagined before. Lots of love for The Apache Software Foundation in it.
↧
Justin Mason: Links for 2017-10-25
Yonatan Zunger’s twitter thread on Twitter’s problem with policy issues
‘I worked on policy issues at G+ and YT for years. It was *painfully* obvious that Twitter never took them seriously.’ This thread is full of good information on “free speech”, nazis, Trump, Gamergate and Twitter’s harrassment problem. (Via Peter Bourgon)
(tags: via:peterbourgonharrassmenttwittergamergatethreadsyoutubegoogle-pluspolicyabusebullyingfree-speechengagement)
↧
↧
Justin Mason: Links for 2017-10-26
Here’s A List Of The Darkest, Strangest Scientific Paper Titles Of All Time | IFLScience
some great papers here (via Emilie)
↧
Shawn McKinney: Why I Ride
Say what you will about cycling, but it affords time for thoughtful contemplation.
Why am I doing this? There are plenty of reasons not, starting with it being hard compared to other forms of transportation.
That the roadways don’t accommodate — we’re at best an annoyance, leading to spats and scuffles of varying severities.
It’s not convenient to commute this way requiring time consuming preparation.
Not a particularly time effective form of transportation — much faster to get into a car and drive.
Complications on arrival not shared with motorist; attired in such a way that is comically out of place of today’s societal norms.
Summing up the pros/cons, it can be hard to make a convincing argument for daily commuting on a bike.
So why do it? Before that can be answered we have to delve into this issue a bit deeper. What are the cons of commuting by car?
- The average automobile spews about 5 metric tons of carbon dioxide into the atmosphere a year.1
- Driving increases stress levels and encourages a sedentary lifestyle.
- The cost to maintain the nation’s highways, roads, bridges and streets is hard to calculate but is probable > $100 billion US.2
- The yearly cost to maintain an automobile about $9,000 US.3
Back to how riding affords time to think — more questions to ponder…
- What happens when everyone on the planet is driving a car? (How much longer can the atmosphere absorb the greenhouse emissions before lasting consequences)
- How much longer can the US government afford to spend sizable portions of our tax revenue maintaining roadways?
- When will petroleum run out and what then?
More riding, more thoughts… at the turn of the century (twentieth), the internal combustion engine (and its supply chain) was perfected, cycling was widespread and automobiles rarely seen on the roads.
We all know what happens next, but what if otherwise? The bicycle the target form of personal transportation and the automobile for public and commercial usage only. Cyclist in the majority; living close by their place of worship, study, work, entertainment, etc… Commuters would be traveling slower and have to talk to one another — maybe better for politics and setting disputes.
What would our environment look like — still polluted with carbons? What of our hospitals — full of unfit patients? What of our cities — divided by giant, ugly roadways or connected by scenic paths?
Is there a middle road? Meanwhile I ride and long for the day everyone follows…

Footnotes
1. Greenhouse Gas Emissions from a Typical Passenger Vehicle
2. What is the federal government’s annual investment in transportation improvements?
3. Annual Cost of Ownership`


↧
Bryan Pendleton: Nothing says changing of the seasons ...
... like noticing that, while we weren't quite paying attention, a group of 8 (!!) paper wasps found their way inside the house and are all clustered against the upper window.
Do paper wasps come in through the chimney? Is there anything one can do about that?
↧